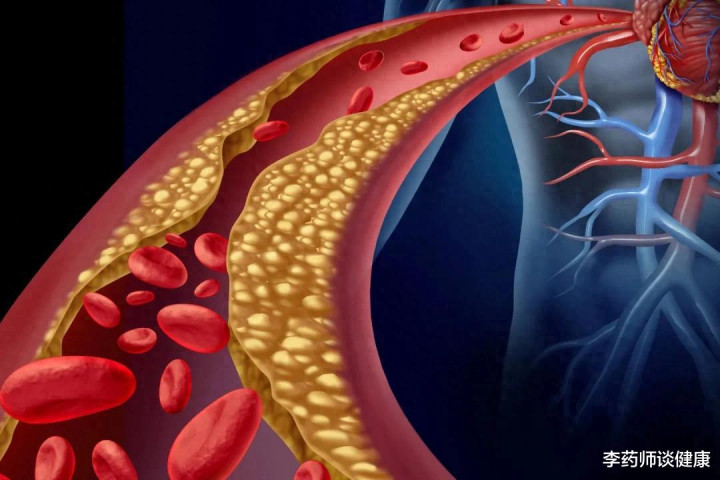
动脉粥样硬化斑块,是导致心脑血管疾病发生的重要风险因素,斑块不但会使血管变窄,影响组织器官血供,如果一旦破裂,还会造成血栓堵塞血管,带来心梗,脑卒中等重大心脑血管事件。正是因为如此,很多朋友对于如何动脉硬化斑块问题,也是非常关注的。
在最近一篇文章的后台,有读者朋友提出这样一个问题:
动脉粥样硬化斑块一旦形成,就不可能再消退逆转了吧?
这种看法也代表了很多朋友的固有观念,但随着对于动脉硬化斑块认识的不断深入,以及冠脉成像技术的不断提升,越来越多的研究发现,动脉血管中的斑块,不但可以通过治疗提高其稳定性,还有可能通过多重的干预手段,实现动脉硬化斑块的“消退”和“逆转”。
动脉硬化斑块是实现稳定和逆转需要经历哪些过程,又有哪些有效措施会实现斑块的逆转呢?一项2024年12月发表在权威期刊 RCM (心血管医学评论)上的一篇综述文章,或许能够为我们给出答案。

在这项综述中,来自中国解放军总医院的医学专家们,对于动脉硬化斑块消退的机制、过程,以及如何实现动脉硬化斑块逆转的临床干预措施,进行了非常详细全面的探讨,我们就结合该综述的内容,为大家解读下动脉硬化斑块逆转的那些事儿。
首先需要明确的是,动脉粥样硬化斑块在一定的干预措施下,是有可能实现逆转消退的,目前临床上对于斑块消退的定义,除了斑块变小,血管内腔直径增加之外,动脉粥样硬化斑块体积的减少,以及斑块易损性相关标志物的减少,也被认为是斑块消退。
斑块消退的5大关键过程
斑块消退的过程,并不是斑块生长过程的反向逆转,想要实现斑块逆转,其中包含了几个重要的过程,包括脂质的移除,细胞增殖的停滞和转化,纤维帽厚度的增加,斑块钙化增加等多个过程,简单为大家总结如下。

1. 胆固醇的排出
斑块的消退首先是增加斑块中脂质的清除能力,在动物实验中也发现,在斑块消退过程中,伴随着反向胆固醇转运的增加。研究表明,强力降低血脂中的低密度脂蛋白胆固醇水平,增加肝脏的摄取和清除能力,都是能够增强胆固醇排出,促进斑块消退的重要方式。
2.炎症反应减弱
动脉粥样硬化本质上是一种慢性炎症疾病。当血管内的炎症减轻时,斑块的不稳定性也会随之降低。文章中提到,多种抗炎治疗可以减少巨噬细胞(一种免疫细胞)在斑块中的积累,降低炎症因子的释放,从而促进斑块稳定。抑制血管内的炎症反应可以防止斑块进一步扩大和破裂。
3. 纤维帽增厚与重塑
斑块表面的纤维帽就像是保护层,它越厚越坚固,斑块破裂的风险就越低。研究指出,在有效对抗慢性炎症后,斑块表面的纤维帽会变得更厚更稳定,这主要归功于平滑肌细胞的增殖和胶原蛋白的合成增加。
4. 坏死核心缩小
斑块中的脂质会被身体的巨噬细胞吞噬,并导致巨噬细胞死亡,这是形成坏死核心的主要成分,因此,去除坏死的巨噬细胞,也能够增强斑块稳定性,促进斑块体积减少。血管内超声(IVUS)研究显示,经过强化降脂治疗,斑块内的坏死核心体积可减少20-30%。
5. 钙化模式改变
斑块钙化的方式对其稳定性有重要影响。研究表明,斑块逆转过程中,点状钙化(不稳定)会逐渐转变为片状钙化(相对稳定),这种钙化模式的改变有助于提高斑块的整体稳定性。CT血管造影研究证实,经过长期治疗,斑块钙化模式确实会趋向于有利斑块稳定的方向变化。
通过上述5个方面,是逐步实现动脉硬化斑块的进一步稳定和消退的重要机制和过程,如果能够通过合理的干预措施和治疗方法,能够逐步实现上述方式,就能够实现稳定斑块,甚至进一步逆转和消退。
做好3点,逆转斑块并不难
在文中不但给出了斑块逆转的具体机制以及影像学评估方法进展,也给出了能够稳定和逆转板块的临床策略,要想实现斑块的稳定和消退,干预措施应包括药物治疗和非药物治疗等多个方面,简单为大家总结逆转斑块的3大关键事项。
1. 强化降脂治疗:斑块逆转的基石
降低血液中的低密度脂蛋白胆固醇(LDL-C)是目前最有效的斑块逆转策略。文中详细介绍了多项临床研究结果,这些研究结果均表明,强化降脂治疗可以显著促进斑块逆转。
ASTEROID研究显示,使用高剂量瑞舒伐他汀治疗24个月后,患者的冠状动脉斑块体积平均减少了6.8%。更令人鼓舞的是,GLAGOV研究证实,当LDL-C水平降至1.8mmol/L以下时,约65%的患者出现了斑块体积的减少。
对于我们中国人而言,高强度他汀的治疗往往耐受性较差, 因此,近年来PCSK9抑制剂类药物的临床应用,这类药物与他汀联合使用,能够进一步加强强化降脂,还能够增强肝脏对于脂质的分解能力,对于逆转斑块提供了更安全高效的联合用药方法。
想要逆转斑块,仅仅降低低密度脂蛋白还是不够的,近年来以非低密度脂蛋白胆固醇为干预靶点的临床研究表明,提升高密度脂蛋白胆固醇水平,降低富含甘油三酯的脂蛋白水平,都能够有助于更好的实现斑块稳定和消退。
临床研究结果显示,IPE(二十碳五烯酸乙酯)能够显著降低甘油三酯,并减少心血管不良事件发生率,研究者认为这种益处不单单是来自于IPE降低甘油三酯的作用,还与其改变血小板功能,抗炎,调节内皮功能障碍等功能有关。
2. 抗炎治疗:斑块稳定的新方向
除了降脂治疗外,抗炎治疗也显示出促进斑块稳定的潜力。CANTOS研究证实,使用抗炎药物卡那单抗可以降低心血管事件风险,而这种获益与降低炎症标志物水平直接相关。
其他抗炎策略,如秋水仙碱和低剂量甲氨蝶呤,也在临床试验中显示出一定的心血管保护作用。这些药物通过减轻血管壁的炎症反应,帮助稳定已形成的斑块。
3. 健康生活方式干预:斑块逆转的基础保障

文章中强调,综合生活方式干预是斑块逆转的基础保障。多项研究表明,健康的饮食模式(如地中海饮食)、规律的体育锻炼、戒烟和体重管理等措施可以协同药物治疗,促进斑块稳定和逆转。
Ornish研究证实,严格的生活方式干预(包括低脂素食饮食、压力管理、适量运动和社会支持)可以在不使用降脂药物的情况下,也可实现冠状动脉斑块的逆转。经过5年时间的随访,实验组患者的冠状动脉狭窄程度平均减少了3.1%,而对照组则增加了11.8%。
总的来说,想要实现稳定斑块,甚至是逆转斑块的目标,健康生活方式的干预必不可少,很多时候,身体健康的真谛并不在吃药多少,而更多的就在生活的点滴当中。
希望这篇文章能够让大家对于如何稳定和逆转动脉硬化斑块,能够有进一步的深入认识,也欢迎大家积极转发分享,让更多人看到靠谱的健康科普知识。